画像内の文字データを抽出してテキスト起こしをするtesseractをCentOS上で試したので作業内容をメモ。
ダウンロードしたtesseract-ocr-3.02.02.tar.gzを展開するとtesseract-ocrというディレクトリができるので移動。
移動先でautogen.shを実行
ログがどんどん流れていきますが、「Running libtoolize」というところでエラー発生。libtoolizeがないということですが、そんなものは存在しません。実体はlibtoolというものらしいので、yumでサクっとインストール。
libtoolをインストール後、再度autogen.shを実行すると、完了しました。
続いてconfigureを実行。
今度はleptonicaがないと言われる・・・。leptonicaってなんだろう・・・。
調べてみると、leptonicaは画像解析ツールらしい。tesseractはleptonicaで処理した解析結果を使って識字するもののようでした。
なので、leptonicaをインストールすることにします。leptonicaのダウンロードはこちらから。
ダウンロードしたバージョンは1.70でした。
展開してコンパイル。
make installの際にsudoするかはログインしているユーザーによりけりです。
無事leptonicaのインストールが完了したら、tesseractのインストールに戻ります。
再度、./configureを実行。今度はうまく通りました。ここまで行けば後はmakeするだけです。
無事インストールは完了しました。
今回テストで使ったのは、こちらの画像。

内容は日付が書かれているデータな訳ですが、うまく認識できるのか!? 早速通してみましょう。
派手にエラーが出ました。確認します。
まず、/usr/local/share/tessdata/eng.traineddataを確認するとファイルがない。
-lで言語指定しない場合は英語をチョイスするようですが、その辞書になるファイルがないということのよう。
早速辞書ファイルを探してみると、tesseractのダウンロードページにありましたのでダウンロード。
展開すると、tessdataディレクトリの下にeng.から始まるファイルが幾つかありましたので、このファイル一式を/usr/local/share/tessdata/以下にコピーします。
コピーが完了したら、再度動作を確認してみます。
特にエラーはなく終了。
できたresult.txtというファイルを見てみると、認識した文字が保存されていました。
結果は良好なようです。
まずは日本語の辞書ファイルを用意します。
こちらも英語と同様、tesseractのダウンロードページにあります。
同じようにダウンロードしてtessdataディレクトリの中のjpn.から始まるファイルをコピーしますが、今度はjpn.traineddataしかありませんでした。
コピーができたら、早速通してみます。
試したテスト画像はこちら。
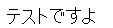
今度は、-lオプションを使って、日本語だと知らせておきます。-lオプションを付けない場合は英語になるようです。
結果は同じくresult.txtに保存されています。
うまく拾っているようです。なかなかやりますね。
このテスト画像ではうまく行きましたが、実際のデータを投入すると結果はあまり芳しくありませんでした。「はじめ」というのが「野まじめ」になる体たらくです。シャレが効いてると言えばそうなのかも知れません。
この設定は、別途confファイルを作成してコマンドラインで渡します。
hoge.confという設定ファイルを作成して、その中でホワイトリストを登録してみます。
hoge.confの中身は以下の通りです。
この設定ファイルを利用して、先ほどの日付画像を通してみます。
結果を見てみると、
ホワイトリストは数字のみなので、ドットは無視されているのが分かります。
同じように日本語のホワイトリストを作って通した結果はよろしくありませんでした。
日本語の認識はよほどゴミが入っていないものか綺麗に表示されているものでないと難しいようです。
このあたりは色情報を飛ばして画像を2値化するなど、手を加える余地がありそうです。
認識率はさておき、使い方は簡単なのでPHPやJavaから利用することもできます。
ソースからコンパイルすれば、ライブラリ的にも使えるので、c++などでパッケージングすることもできます。ライセンスもapache2.0ライセンスと使い勝手が良い点もいいです。
導入編 tesseractのインストール
今回はソースコードからコンパイル。ソースコードはこちらにあります。インストールしたバージョンは最新版(2014.02.17現在)の3.02。ダウンロードしたtesseract-ocr-3.02.02.tar.gzを展開するとtesseract-ocrというディレクトリができるので移動。
移動先でautogen.shを実行
./autogen.sh
ログがどんどん流れていきますが、「Running libtoolize」というところでエラー発生。libtoolizeがないということですが、そんなものは存在しません。実体はlibtoolというものらしいので、yumでサクっとインストール。
sudo yum install libtool
libtoolをインストール後、再度autogen.shを実行すると、完了しました。
続いてconfigureを実行。
./configure
今度はleptonicaがないと言われる・・・。leptonicaってなんだろう・・・。
調べてみると、leptonicaは画像解析ツールらしい。tesseractはleptonicaで処理した解析結果を使って識字するもののようでした。
なので、leptonicaをインストールすることにします。leptonicaのダウンロードはこちらから。
ダウンロードしたバージョンは1.70でした。
展開してコンパイル。
./configure make sudo make install
make installの際にsudoするかはログインしているユーザーによりけりです。
無事leptonicaのインストールが完了したら、tesseractのインストールに戻ります。
再度、./configureを実行。今度はうまく通りました。ここまで行けば後はmakeするだけです。
make & sudo make install
無事インストールは完了しました。
動作編
インストールが完了したら、適当な画像を通して、動作を確認してみます。今回テストで使ったのは、こちらの画像。

内容は日付が書かれているデータな訳ですが、うまく認識できるのか!? 早速通してみましょう。
tesseract test.png result Error opening data file /usr/local/share/tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.
派手にエラーが出ました。確認します。
まず、/usr/local/share/tessdata/eng.traineddataを確認するとファイルがない。
-lで言語指定しない場合は英語をチョイスするようですが、その辞書になるファイルがないということのよう。
早速辞書ファイルを探してみると、tesseractのダウンロードページにありましたのでダウンロード。
展開すると、tessdataディレクトリの下にeng.から始まるファイルが幾つかありましたので、このファイル一式を/usr/local/share/tessdata/以下にコピーします。
cp -frp ./eng.* /usr/local/share/tessdata/
コピーが完了したら、再度動作を確認してみます。
tesseract test.png result Tesseract Open Source OCR Engine v3.02.02 with Leptonica
特にエラーはなく終了。
できたresult.txtというファイルを見てみると、認識した文字が保存されていました。
16. 8.27
結果は良好なようです。
日本語の認識を試す
せっかくなので、日本語の認識テストもしてみます。まずは日本語の辞書ファイルを用意します。
こちらも英語と同様、tesseractのダウンロードページにあります。
同じようにダウンロードしてtessdataディレクトリの中のjpn.から始まるファイルをコピーしますが、今度はjpn.traineddataしかありませんでした。
コピーができたら、早速通してみます。
試したテスト画像はこちら。

tesseract jpn_test.png result -l jpn Tesseract Open Source OCR Engine v3.02.02 with Leptonica
今度は、-lオプションを使って、日本語だと知らせておきます。-lオプションを付けない場合は英語になるようです。
結果は同じくresult.txtに保存されています。
テス卜ですよ
うまく拾っているようです。なかなかやりますね。
このテスト画像ではうまく行きましたが、実際のデータを投入すると結果はあまり芳しくありませんでした。「はじめ」というのが「野まじめ」になる体たらくです。シャレが効いてると言えばそうなのかも知れません。
文字種を制限して通す
画像内に現れる文字があらかじめ分かっている場合は、ホワイトリストを作って通すと、識字率はアップします。この設定は、別途confファイルを作成してコマンドラインで渡します。
hoge.confという設定ファイルを作成して、その中でホワイトリストを登録してみます。
hoge.confの中身は以下の通りです。
tessedit_char_whitelist 0123456789
この設定ファイルを利用して、先ほどの日付画像を通してみます。
tesseract test.png result -l eng ./hoge.conf Tesseract Open Source OCR Engine v3.02.02 with Leptonica
結果を見てみると、
16 827
ホワイトリストは数字のみなので、ドットは無視されているのが分かります。
同じように日本語のホワイトリストを作って通した結果はよろしくありませんでした。
日本語の認識はよほどゴミが入っていないものか綺麗に表示されているものでないと難しいようです。
このあたりは色情報を飛ばして画像を2値化するなど、手を加える余地がありそうです。
認識率はさておき、使い方は簡単なのでPHPやJavaから利用することもできます。
ソースからコンパイルすれば、ライブラリ的にも使えるので、c++などでパッケージングすることもできます。ライセンスもapache2.0ライセンスと使い勝手が良い点もいいです。
参考になりました
返信削除